L'avènement de la synthèse de programme
Article à paraître dans Interstices
La notion de programme est au centre de l'informatique : c'est l'intermédiaire entre l'utilisateur et la machine, le moyen par lequel un humain peut communiquer à la machine des opérations à effectuer pour réaliser une tâche de manière automatique. Les langages de programmation facilitent cette communication : il en existe une très grande variété chacun adapté aux tâches envisagées, par exemple pour créer un site internet, mettre différents ordinateurs en réseau, ou contrôler un drone. Il n'en reste pas moins qu'écrire un programme est une tâche difficile : non seulement elle est coûteuse en temps et en énergie, elle requiert à la fois une expertise en programmation et une compréhension fine de la tâche à réaliser.
L’objectif de la synthèse de programme est de rendre accessible à tous, experts et non-experts, la conception de programmes : au lieu d’écrire un programme, l’utilisateur décrit la tâche qu’il veut réaliser et le programme est automatiquement généré (on dit synthétisé) à partir de cette spécification.
La synthèse de programme est un des plus anciens rêves de l’intelligence artificielle : c’est un pas de plus vers l’automatisation des tâches. Longtemps considérée comme un objectif lointain (comme l’était l’idée de battre les humains au Go !), la synthèse de programme est maintenant mise en pratique dans de nombreux contextes académiques et industriels. Commençons par une petite sélection non-exhaustive de succès récents :
- Les logiciels d’éditions de tableurs, dont Microsoft Excel ou LibreOffice Calc, permettent d’effectuer des tâches avancées de traitement de données par l’écriture de macros. Une macro est un court programme, par exemple une suite d’instructions tenant sur une ligne, écrit dans un langage de programmation spécifique. Peu d’utilisateurs maîtrisent ces langages de macros, et l’abondance de questions très basiques sur les forums dédiés atteste de la difficulté pour l’utilisateur lambda d’écrire des macros. Le logiciel FlashFill a été développé par Microsoft Research, et intégré à Microsoft Excel depuis sa version 2013. Il automatise la conception de macros : il suffit de donner un ou plusieurs exemples et de demander à FlashFill de trouver, ou plutôt synthétiser, la macro correspondante. C’est tellement intuitif et simple d’utilisation que le concept a été repris par Google en 2020 : SmartFill est l’équivalent de Flashfill dans Google Sheets, comme illustré dans la figure animée ci-dessous.

- La modélisation est l’étape consistant à abstraire un système réel (un pendule, un serveur, une colonie de fourmis) en un modèle mathématique. Au cours de la modélisation, on distingue deux aspects : la structure du modèle, qui décrit la dépendance entre les différentes composantes du système, et ses paramètres numériques. Les méthodes d’apprentissage automatique supposent une structure donnée et cherchent les paramètres. Par exemple, le problème de la régression linéaire suppose qu’il existe une droite (c’est la structure) correspondant à un échantillon de points dans le plan, et cherchent les paramètres de cette droite, à savoir pente et ordonnée à l’origine. L’illustration ci-dessous montre le processus d’apprentissage du modèle (une droite) sur les données. La synthèse de programme permet d’apprendre la structure d’un modèle mathématique sous la forme d’un programme, généralisant de nombreux modèles utilisés en apprentissage automatique.
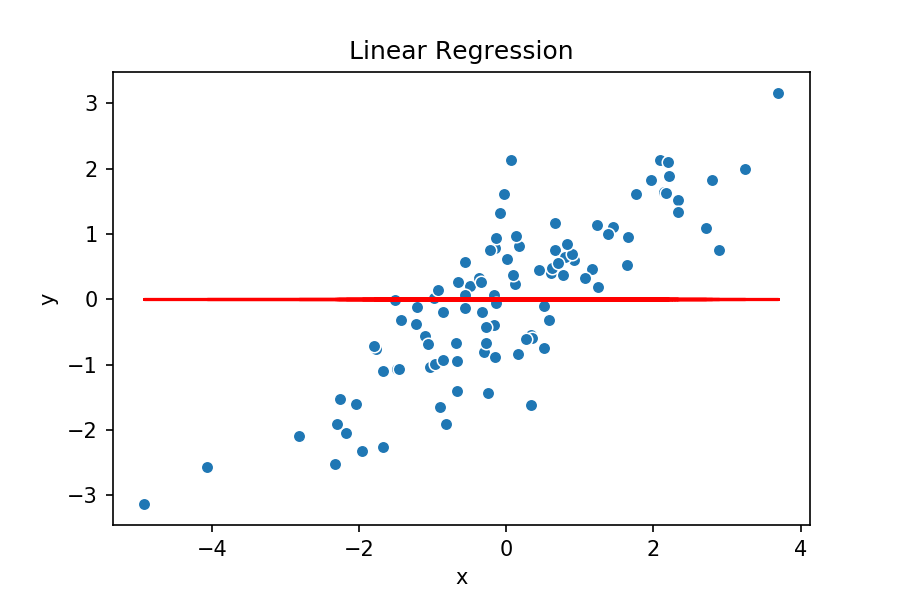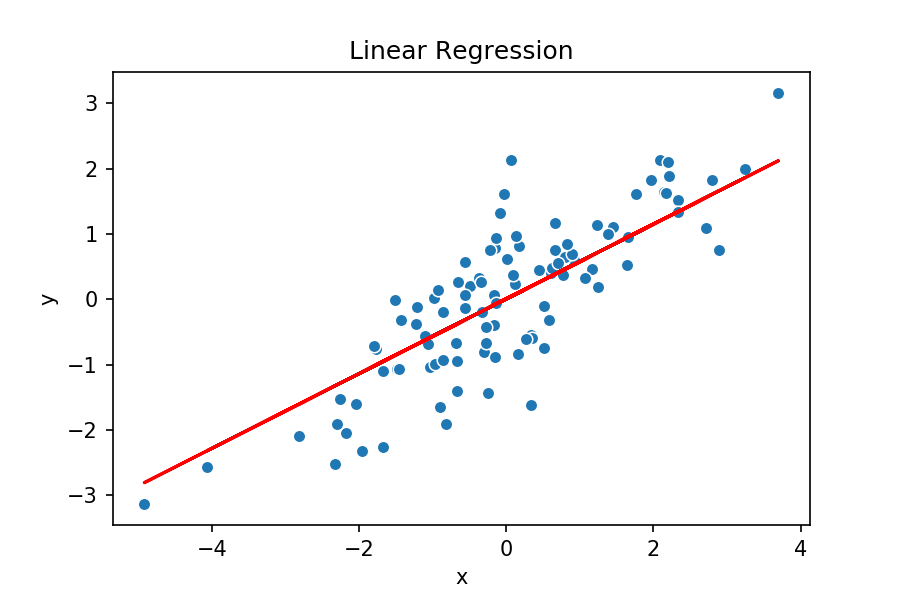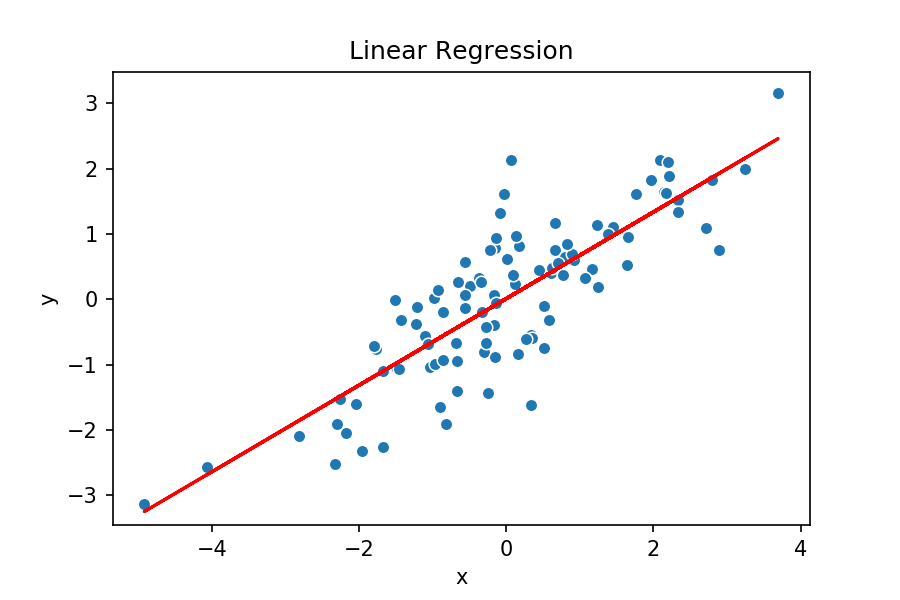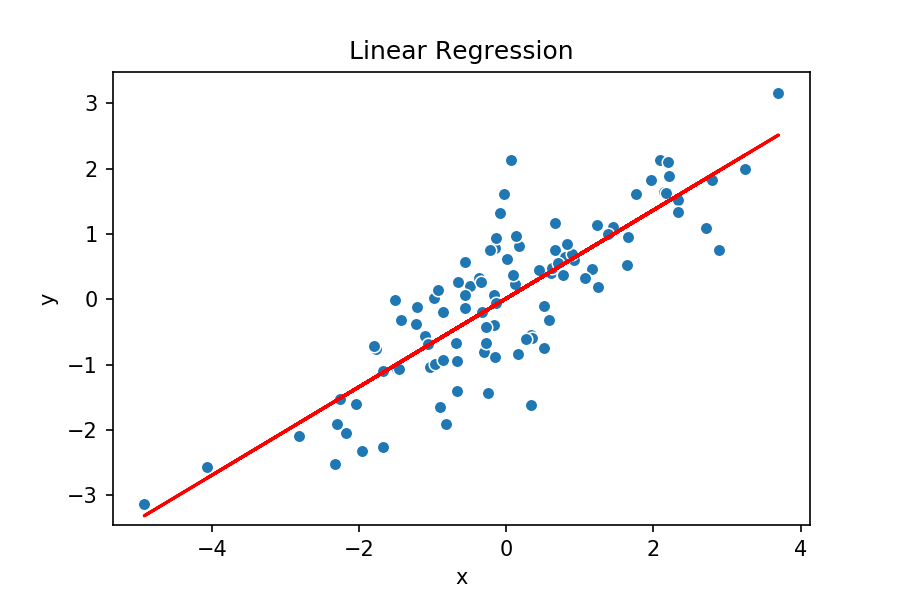
Prenons un exemple de modélisation, la prédictions aux échecs : étant donné le classement ELO de deux joueurs, comment prédire le résultat d’un match entre ces deux joueurs $A$ et $B$? Notons $R_A$ et $R_B$ les deux valeurs reflétant le niveau des joueurs, le système ELO prédit que le joueur A gagne avec probabilité \(\frac{10^{R_A / 400}}{10^{R_A / 400} + 10^{R_B / 400}}\). D’où vient cette formule ? Elle est issue d’un modèle mathématique, qui peut être plus ou moins fidèle à la réalité. La synthèse de programmes permet de générer une telle formule directement à partir des statistiques existantes, c’est ce que fait par exemple l’outil académique PSketch : à partir d’échantillons numériques du système, il produit une formule représentant au mieux les observations.
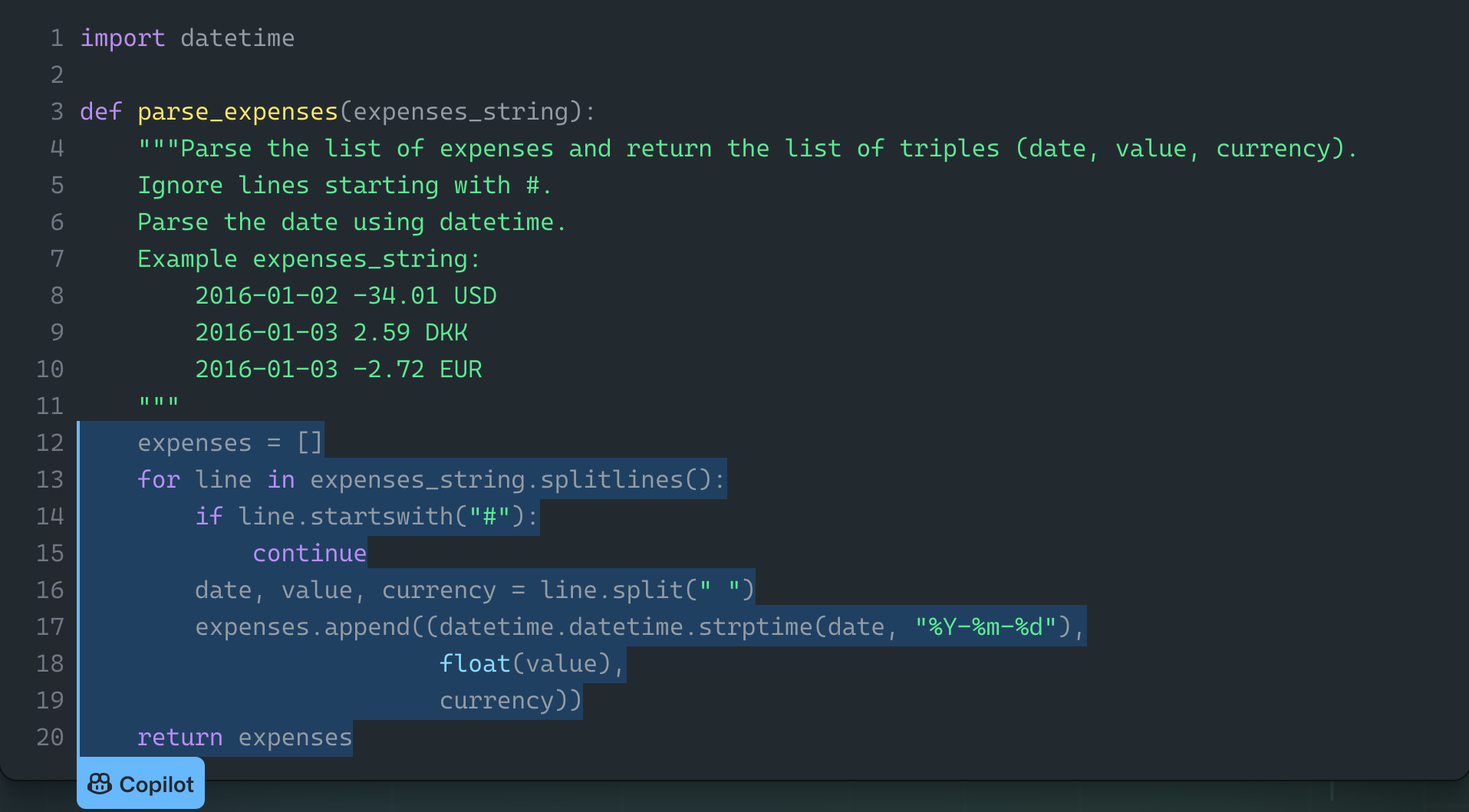
- Les environnements de développement (EDI, ou IDE en anglais pour “integrated development environment”) sont des ensembles d’outils facilitant la production de code. Il existe plusieurs applications de la synthèse de programme dans ce sens : la “super-optimisation” de code, qui permet de remplacer un code par un autre plus efficace, ou la réparation de code, qui modifie un code existant pour en enlever des bugs potentiels. En 2021 OpenAI a annoncé la sortie d’un outil allant encore plus loin : Copilot est présenté comme un compagnon de programmation capable d’écrire lui-même une partie du code. Copilot peut lire des spécifications en langue naturelle et en proposer une implémentation, comme illustré ci-dessous : la spécification est donnée par l’utilisateur en vert sous la forme d’un commentaire en anglais (DOCSTRING), et Copilot propose l’implémentation qui suit.
Cette courte liste d’applications récentes de la synthèse de programme est loin d’être exhaustive : ce survol récent décrit d’autres applications. Il y a deux choses à retenir :
- l’objectif n’est pas de synthétiser de longs programmes, mais plutôt des programmes courts et indépendants, souvent destinés à être directement exécutés sur des exemples donnés par l’utilisateur,
- parfois la finalité n’est pas de produire le programme tout entier, mais plutôt d’aider le programmeur dans sa tâche, créant une interaction naturelle entre l’humain et la machine.
La synthèse de programme au 21ème siècle
Pour mieux comprendre l’état de la recherche actuelle, dressons un rapide panorama des techniques utilisées, à travers trois aspects : le choix du langage, la spécification, et l’algorithme de recherche.
Le choix du langage
La première question à se poser est : dans quel langage veut-on synthétiser des programmes ? En synthèse de programme il est très courant d’utiliser des langages que l’on créé pour un usage précis, spécifiques à un domaine d’application (“domain specific language”, ou DSL, en anglais), dont les macros d’Excel forment un exemple.
L’étude des langages de programmation nous a appris qu’il est souvent utile de voir un programme comme un arbre (“abstract syntax tree”, ou AST, en anglais), et de représenter l’ensemble des programmes à l’aide d’une grammaire hors-contexte. Cet article d’Interstices développe l’utilisation des grammaires hors-contexte pour les langages de programmations.
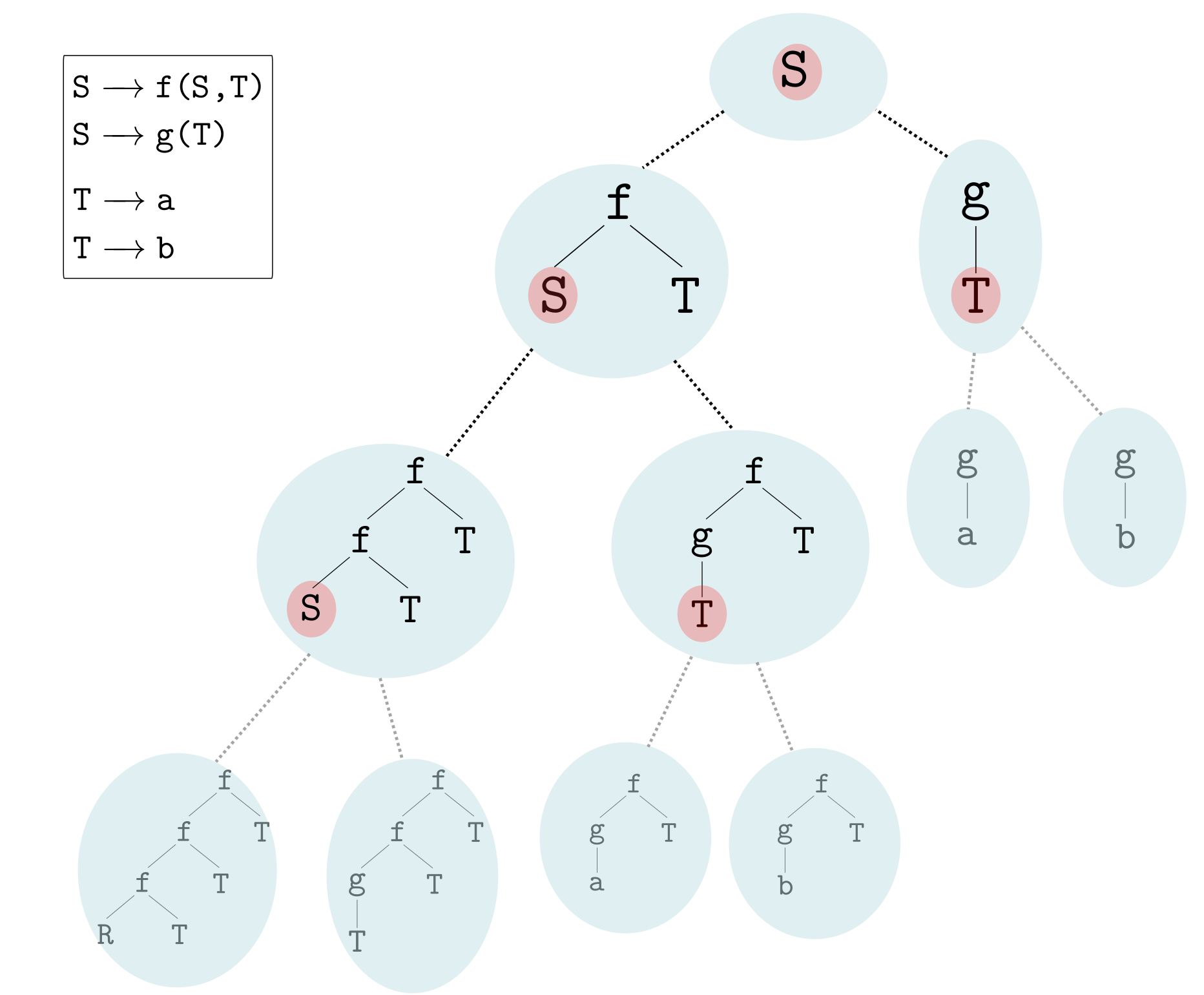
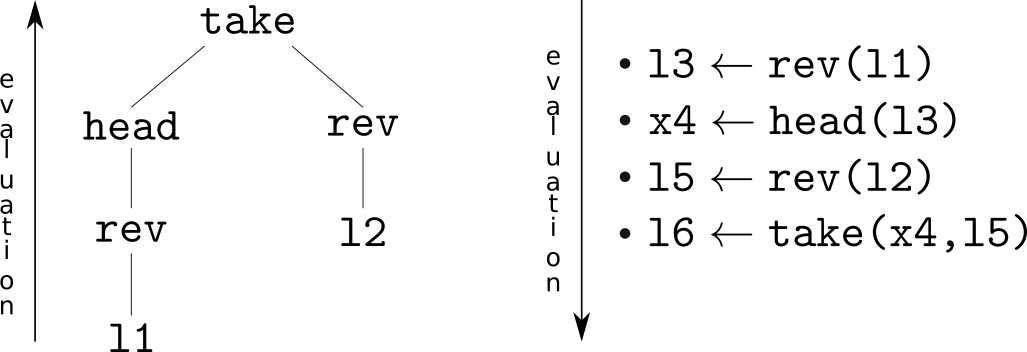
La figure ci-dessus montre une grammaire hors-contexte : sans entrer plus dans les détails, il s’agit d’une représentation formelle permettant d’abstraire des programmes de manière plus facile à comprendre et manipuler par des algorithmes. Chaque arbre représente un programme. Ici c’est abstrait, parce que les symboles (f,g,a,b) n’ont pas de signification. L’exemple ci-dessous rend les choses plus concrètes : les symboles sont des primitives du langage de programmation, à savoir take, head, et rev, et des variables l1 et l2, qui sont les entrées du programme. Ici une “primitive” est une brique de base du langage de programmation, par exemple “head” returne le premier élément d’une liste.
Le même programme est représenté par un arbre (à gauche) et de manière plus classique par une suite de primitives (à droite).
Ainsi en construisant un DSL (langage de programmation) réduit à son minimum et utilisant une syntaxe épurée, on obtient un précieux levier algorithmique permettant de raisonner sur les programmes, mettant à profit des dizaines d’années de recherche sur les langages de programmation et les langages formels (ici, grammaires hors-contexte). C’est dans ce contexte qu’est née une des idées qui a révolutionné la synthèse de programme ces dix ou quinze dernières années, due à Armando Solar-Lezama et communément appelée le “sketching” : en plus de la spécification, l’utilisateur décrit une trame (un “sketch”) du programme. La trame peut contenir des omissions de différentes natures : des constantes à choisir, des programmes à substituer, ou mêmes des prédicats à décrire. L’argument est le suivant : bien qu’il soit compliqué d’écrire le programme tout entier, il est en général facile d’en décrire la structure, et cela peut grandement faciliter la synthèse de programme en restreignant considérablement l’ensemble des programmes potentiels.
La syntaxe de langages de programmation courants et génériques tels que Python est très complexe, puisqu’elle doit être suffisamment flexible pour être utilisable par le programmeur quelle que soit la tâche. Pour cette raison, les représentations formelles décrites ci-dessus sont difficiles à mettre en pratique. De fait, l’outil Copilot, dont l’objectif est de générer du code dans des langages génériques tels que Python, considère un programme simplement comme un bloc de texte, ignorant sa structure. En effet, Codex, le logiciel derrière Copilot et développé par OpenAI, est issu du modèle GPT3 dont l’objectif initial est de faire du traitement de langues naturelles (français, anglais,…), et en particulier de la traduction. Ce n’est que récemment qu’OpenAI a exploré l’idée d’utiliser les architectures de réseaux de neurones manipulant des langues naturelles pour d’autres langues, à savoir les langages de programmation !
La spécification
Une fois le choix du langage effectué, se pose celui de la spécification : comment l’utilisateur peut-il décrire le programme ?

L’image ci-dessus illustre bien la difficulté : la spécification doit être à la fois complète et précise, tout en étant facile à formuler par l’utilisateur. La situation n’est pas aussi désespérée : dans de nombreuses applications des spécifications incomplètes sont souvent suffisantes.
Plusieurs types de spécifications ont été étudiées :
- La plus simple est de donner quelques exemples. Si le programme doit réaliser une fonction, à savoir calculer quelque chose sur une entrée, alors une poignée de paires entrées / sorties permet souvent de décrire un programme de manière assez précise. Ce cadre est appelé Programmation par l’exemple (“programming by example” en anglais), et a été popularisé par FlashFill (décrit ci-dessus). Bien que très naturel, ce type de spécification est très incomplet : il peut exister beaucoup de programmes respectant les quelques exemples donnés, mais qui ne font pas du tout ce que l’utilisateur avait en tête !
- Un raffinement de la programmation par l’exemple est la programmation par la démonstration : ici il s’agit de décrire l’exécution du programme sur une poignée d’exemples. Prenons un exemple concret : si l’on veut décrire la fonction factorielle, on peut soit donner quelques exemples : 3! = 6 et 4! = 24, mais on peut être plus précis et décrire le calcul qui a amené à ce résultat, ici 3! = 3 * 2 et 4! = 4 * 3 * 2. On voit que c’est plus précis, et donc plus facile de synthétiser un programme à partir d’une telle démonstration. Par le même mouvement, c’est plus compliqué pour un utilisateur à décrire !
- Si l’on souhaite donner une spécification complète et précise, mais pas opérationnelle, on utilise des formalismes logiques. Considérons l’exemple du programme qui trie une liste d’entiers par ordre croissant, par exemple sur la liste d’entrée [4,2,5,1], le programme retourne [1,2,4,5].
Sa spécification logique pourrait s’écrire comme suit, en notant l1 la liste en entrée et l2 la liste en sortie :
- la liste l2 est une permutation de la liste l1 : pour tout i, il existe j tel que l2[i] = l1[j], et pour tout i, il existe j tel que l1[i] = l2[j],
- la liste en sortie est triée : pour tout i < j, on a l2[i] < l2[j].
Comme on le voit sur cet exemple, la spécification logique, bien que complète et précise, ne donne pas directement l’algorithme : elle décrit seulement ce qu’il doit faire. De fait, il y a encore beaucoup de travail pour passer de la spécification à l’algorithme !
- Une autre possibilité est de décrire le programme en langue naturelle : c’est ce que fait Copilot. Dans l’exemple donné tout au début de cet article, ce que le programme doit faire en décrit en anglais. L’avantage est indéniablement que c’est la manière la plus facile pour l’utilisateur de donner une spécification. Mais ce type de spécification peut être très imprécis ! Par exemple, comment interpréter “cet algorithme trie la liste et enlève le premier élément” : s’agit-il de trier, puis d’enlever le premier élément, ou dans l’autre sens ?
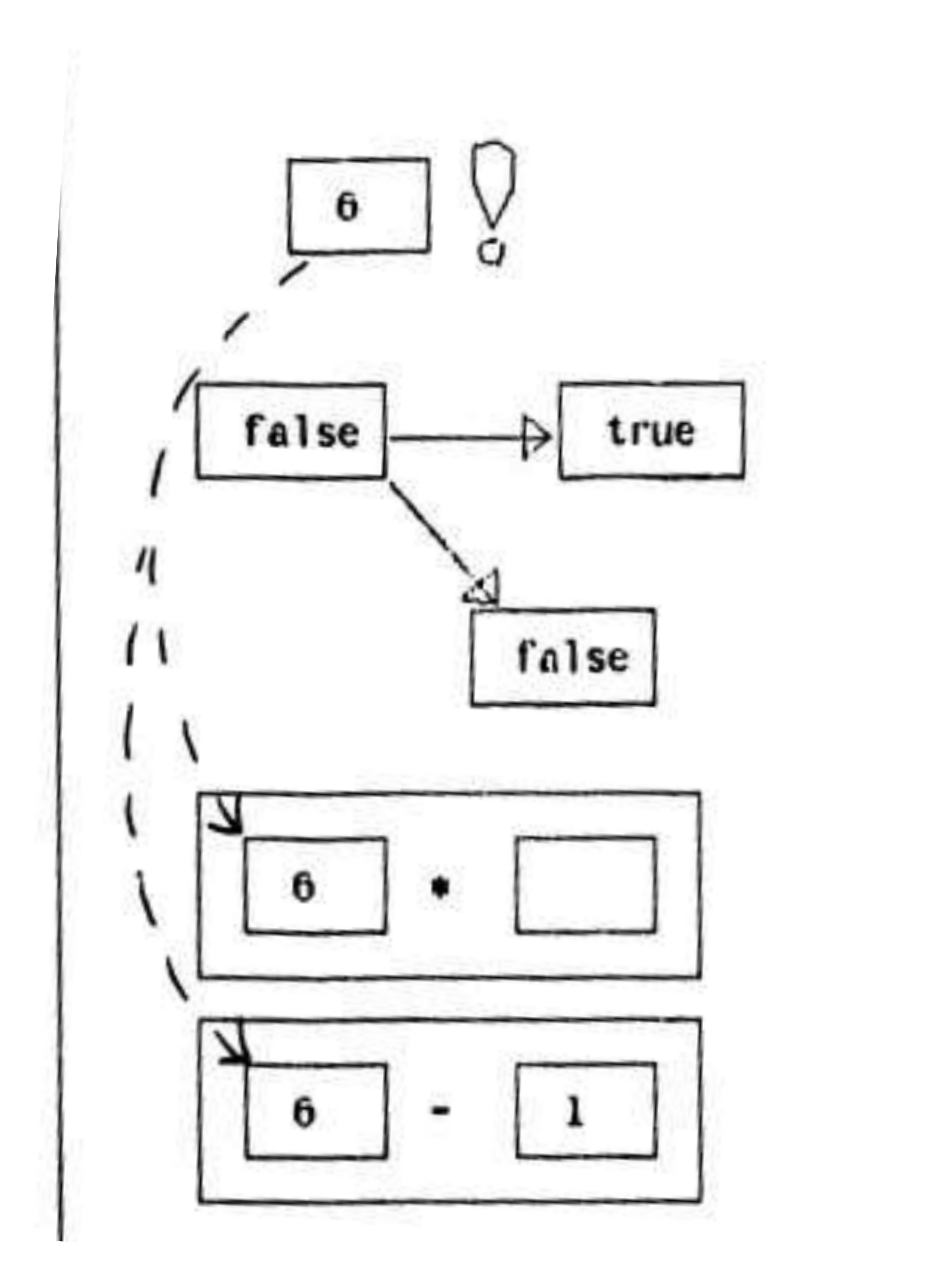
- De nombreuses approches de spécifications graphiques ont été développées. Par exemple, le logiciel Pygmalion a été écrit en 1975 avec pour objectif de programmer à partir d’exemples, en remplaçant les concepts habituels de la programmation (variables, structures de données) par des visualisations interactives. Pygmalion est un ancêtre des langages graphiques, qui ont donné lieu aux interfaces graphiques que nous utilisons quotidiennement pour interagir avec des machines. La figure ci-dessous représente l’exécution d’un programme calculant la factorielle de 6. L’utilisateur décrit les opérations nécessaires et décrit l’exécution du programme sur un ou plusieurs exemples afin de synthétiser le programme.
L’algorithme de recherche
Le défi algorithmique de la synthèse de programme est un problème de recherche : étant donné un ensemble de programmes, comment trouver dans cet ensemble un programme satisfaisant notre spécification ? Nous présentons ici les trois approches les plus importantes.
Énumération
C’est l’approche la plus simple et la plus ancienne : pour trouver le bon programme, il suffit de les énumérer un par un, et de vérifier pour chacun s’il satisfait la spécification. L’énumération peut être effectuée de manière très simple et efficace en se basant sur les représentations formelles à base de grammaires hors-contexte, qui permet de générer plusieurs dizaines de milliers de programmes par seconde. Sa simplicité permet d’enrichir cette approche avec de nombreuses optimisations, la rendant très compétitive, voici quelques exemples :
- l’élagage (ou “pruning” en anglais), a pour objectif d’abandonner des branches entières de l’énumération si on peut déterminer qu’elle ne contient pas de programme solution,
- l’évaluation partagée, qui mutualise autant que possible l’évaluation des programmes pour déterminer s’ils satisfont la spécification,
- la recherche en parallèle, en divisant la recherche entre plusieurs processeurs travaillant indépendamment,
- le raffinement par abstraction (ou “abstraction refinement” en anglais), qui décompose la recherche en plusieurs niveaux d’abstraction.
Résolution de contraintes
L’explosion de performances des logiciels de résolution de contraintes, à commencer par la satisfaisabilité d’une formule booléenne (SAT), mais surtout avec les SMT (Satisfiability Modulo Theories) pour les théories logiques plus avancées, ont directement impacté les progrès en synthèse de programme. L’idée est de réécrire la question originale, à savoir l’existence d’un programme, comme un ensemble de contraintes logiques. Prenons un exemple simple : la fonction max qui prend deux entiers et retourne le maximum des deux satisfait les contraintes $f(x,y) >= x$ et $f(x,y) >= y$. Dit autrement, on peut synthétiser la fonction max à l’aide d’un logiciel de résolution de contraintes en demandant une fonction $f$ satisfaisant les contraintes $f(x,y) >= x$ et $f(x,y) >= y$. Mais il existe d’autres fonctions satisfaisant ces contraintes : par exemple l’addition ! C’est pour cela que les approches par résolution de contraintes fonctionnent de manière itérative, en ajoutant de nouvelles contraintes au fur et à mesure, jusqu’à trouver le bon programme. Dans notre exemple, on peut ajouter par exemple la contrainte qui dit $f(x,y)$ est soit $x$ soit $y$. On obtiendra ainsi l’unique solution à notre ensemble de contraintes : la fonction max.
L’approche CEGIS (Counterexample Guided Inductive Synthesis) décrit comment utiliser un logiciel de résolution de contraintes pour la synthèse de programme. Elle est décrite par exemple dans cet article accessible aux non-spécialistes et en anglais. Depuis son introduction en 2006, c’est une technique de référence permettant d’obtenir d’excellents résultats en pratique.
Apprentissage automatique
En 1989 Solomonoff avait déjà proposé l’idée de guider la recherche de programmes en utilisant des prédictions sur les propriétés du programme. Ceci a donné lieu à une première utilisation de l’apprentissage automatique en 2013, mais c’est véritablement en 2017 avec le logiciel DeepCoder que l’utilisation d’apprentissage profond a ouvert de nouvelles perspectives. L’idée de DeepCoder est d’utiliser un réseau de neurones pour prédire les primitives utilisées dans le programme à partir des exemples donnés par l’utilisateur. Intuitivement, le réseau de neurones observe des corrélations entre les paires entrée / sortie, et en déduit (des prédictions sur) les opérations faites par le programme.
Par exemple, imaginons un programme manipulant des listes d’entiers : la figure ci-dessous donne un exemple de programme (à gauche) et un exemple d’entrée / sortie pour ce programme (à droite). Le programme que l’on cherche fait la chose suivante : il extrait le plus petit entier positif $n$ de la liste d’entrée (pour cela, il la trie avec SORT, enlève les entiers négatifs avec FILTER, et prend le premier élément avec HEAD), et retourne la liste triée privée des $n$ premiers éléments avec DROP. Dans l’exemple donné à droite, le plus petit entier positif de la liste d’entrée est 3, donc la liste en sortie est celle en entrée triée et privée des trois premiers éléments.

La question est : quelle information peut-on obtenir du programme en regardant la paire entrée / sortie ? En observant que tous les éléments de la liste de sortie apparaissent dans la liste d’entrées, mais qu’il n’en reste qu’une partie, on subodore que la liste ait été triée par la primitive SORT, et que la primitive FILTER a été utilisée. Comment ces deux primitives sont combinées pour créer le programme est une question déléguée à un algorithme de recherche, le réseau de neurones se contente de prédire l’apparition de SORT et de FILTER.
Depuis 2017, les progrès les plus impressionnants en synthèse de programme viennent de l’apprentissage automatique, utilisé de manière très diverse. Par exemple, DreamCoder permet au réseau de neurones de “rêver” : en combinant aléatoirement des primitives existantes, DreamCoder en créé de nouvelles pour enrichir le DSL dans le but de faciliter la synthèse.
Perspectives
La synthèse de programme est en pleine expansion, et ses succès proviennent maintenant de la combinaison de techniques issues des langages de programmation d’une part, et d’apprentissage automatique d’autre part. Une captivante introduction à l’approche “synthèse de programme guidée par la syntaxe” (SyGuS) est accessible dans cet article en anglais.
Il reste encore beaucoup de chemin : François Chollet, chercheur à Google, a proposé en 2019 le challenge ARC (Abstraction and Reasoning Corpus) pour la synthèse de programme. Il s’agit d’une longue liste de casse-têtes, présentés sous la forme de grilles à compléter. N’importe quel enfant peut résoudre la plupart de ces casse-têtes, même s’il ne sait pas lire, et quelque soit son environnement culturel ou social. Par contre, aucun logiciel existant n’est capable de résoudre ne serait-ce que la moitié de ces grilles !
Références
En plus des références donnés dans l’article, les notes de cours en anglais d’Armando Solar-Lezama du MIT sont une mine d’informations presque inépuisable .