DeepCoder, Learning to write programs
This post is a short presentation of the DeepCoder paper, which proposed in 2017 a very interesting line of attack for improving program synthesis using machine learning.
The DeepCoder paper can be found here. It is a great source of inspiration for the DeepSynth Momentum project. The goal of this post is to quickly present some key ideas, as an introduction to some follow-up works of ours.
All images are taken from our technical report, a joint work with Judith Clymo, Haik Manukian, Adria Gascon, and Brooks Paige.
The Domain Specific Language (DSL)
The first design choice for program synthesis is the programming language, which is usually called DSL. In the case of DeepCoder, they came up with a new DSL that we introduce here. Programs manipulate list of integers in [-2^8+1,2^8-1]. A program is simply is sequence of instructions (so, no recursion, no loops). Each instruction is chosen in a list of 38 high-level list manipulating functions, such as sort (sorting the list), filter(>0) (removing all negative elements from the list), map(+1) (adding one to each element of the list), and so on. Here is an example: the program on the left hand side, and an example I/O (input / output) on the right hand side.

A legitimate concern is whether this DSL is reasonable and experimental results on this DSL would carry over to other DSLs. I find this argument somehow compelling: the DSL was expressive enough to write solutions to some online programming competitions with a few (at most 5) lines programmes.
The next question is how long programs are we looking at. It turns out that 4 and 5 lines programs already can produce complex procedures.
A nice property of the DSL is that a program is syntactically very simple: it can be seen as a sequence of numbers in [1,38]. If we restrict to programs of length say 5, we can organise the set of all programs in a tree, the leaves being the programs of length 5. There are 38^5 such programs, which is close to 10^9, that’s a lot. The most naive search procedure would simply sweep through the tree of all programs, say in a DFS way. It would not terminate for length 5.
Programming by Example (PbE)
The second design choice for program synthesis is the way the specification is given. In the programming by example paradigm, the specification is a few examples in the form of I/O (input / output). The success story coming out of programming by example is FlashFill, developed by Gulwani at Microsoft Research, and included in Excel since 2013!
For the DeepCoder framework, the choice was to use 5 I/O.
The full problem description is: given 5 I/O, find a program satisfying these I/O.
A machine learning model for describing heuristics
DeepCoder’s line of attack is based on the following two observations:
- Not all programs are equally likely: there is a bias in the way programs are written (for instance, few programs use both filter(>0) and filter(<0))
- The I/O give some indications about the program (for instance, if all outputs are sorted, it is likely that the program contains a sort)
The line of attack is illustrated in the following figure.
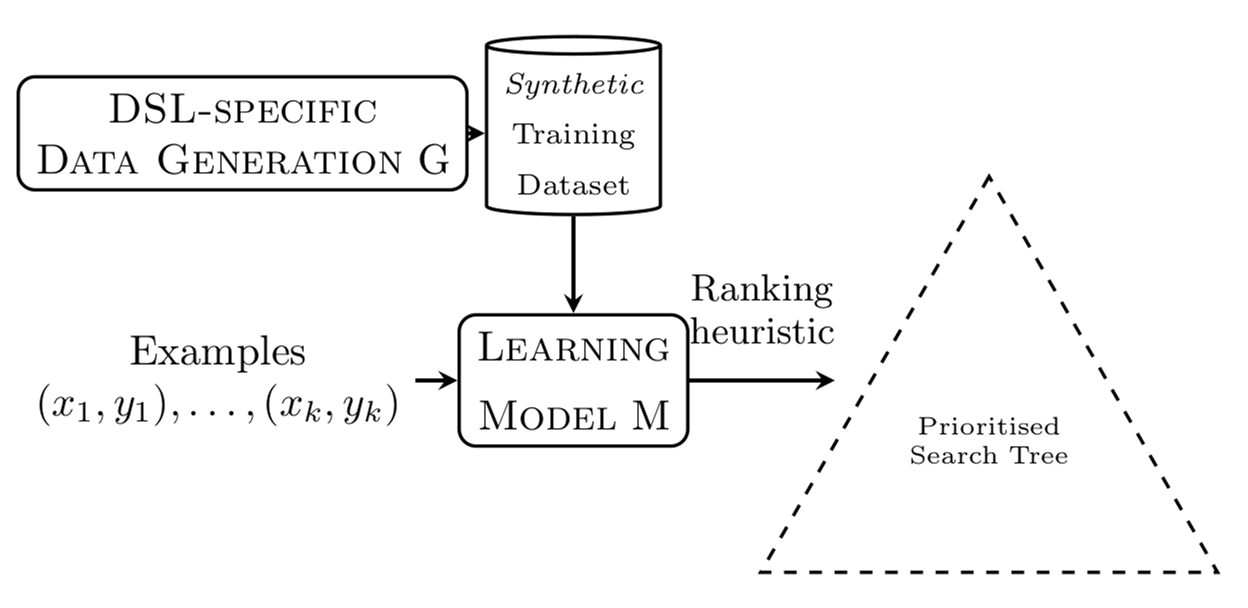
In words: the idea is to describe a heuristic using a machine learning model, typically a neural network. The neural network takes as input the 5 I/O and outputs for each function the likelihood (a number in [0,1]) that the function is used in a program satisfying these I/O. The search procedure is then a biassed DFS: the most likely functions according to the neural network are tried first.
Data generation
An important question is: how do we train the neural network? The obvious answer is: using millions of programs and I/O. But such a dataset may not be available, and indeed since the chosen DSL was created for these experiments, there are no datasets of programs and I/O. Hence the actual answer: by generating millions of programs and I/O, ie by creating a synthetic dataset.
How to do data generation in a reasonable way, to ensure that the neural network indeed learns interesting information, is exactly what we focussed on in our recent work. A dedicated blog post will come soon!
Improving the search procedure
Are we indeed using the information collected by the neural network in the optimal way? For instance, the network outputs for each function the likelihood in the form of a number in [0,1]. We only use this evaluation to order all functions by likelihood.
The question whether there are more accurate search procedures is what we are focussing on now.